
Vidu Q2 – 生数科技推出的新一代图生视频模型,适合制作高质量视频
生数科技推出了新一代图生视频大模型 ——Vidu Q2,为用户提供了前所未有的视觉体验。Vidu Q2的最大亮点在于其对极致表情变化的精准捕捉,结合了推拉运镜技术,提升了视频的生成速度与语义理解能力...

Neovate Code – 蚂蚁集团开源的AI编程助手,支持开发者用自然语言描述编程需求
neovate code 是由蚂蚁集团推出的开源智能编程助手,致力于全面提升开发效率。该工具具备深度理解代码库的能力,能够遵循项目现有的编码风格,支持通过插件系统灵活扩展功能。目前以命令行工具(cli...

CWM – Meta开源的代码世界模型,自动化修复代码中的错误
Meta 刚发布的这个 CWM,是一个 320 亿参数的开放权重 LLM,以推动基于世界模型的代码生成研究。该模型通过模拟代码执行过程,不仅生成代码,还能理解代码的动态行为,预测执行结果,并具备自我调...

AI Quests – 谷歌联合斯坦福推出的AI教育工具,帮助学生理解AI的实际应用
谷歌推出了一款专为11-14岁学生设计的免费教育游戏化产品“AI Quests”,旨在通过沉浸式游戏体验提升学生的AI素养。AI Quests的独特之处在于它与谷歌的实际研究紧密联系,将中学生与前沿科...

Mixboard – 谷歌推出的AI画板工具,快速将想法可视化
谷歌推出实验性 AI 工具 Mixboard,该工具由Banana提供支持,号称能把任何想法都即时可视化。主打“开放画布”与生成式 AI 创意,可从文本提示或预制板开始,生成包括家居装饰、产品设计等多...
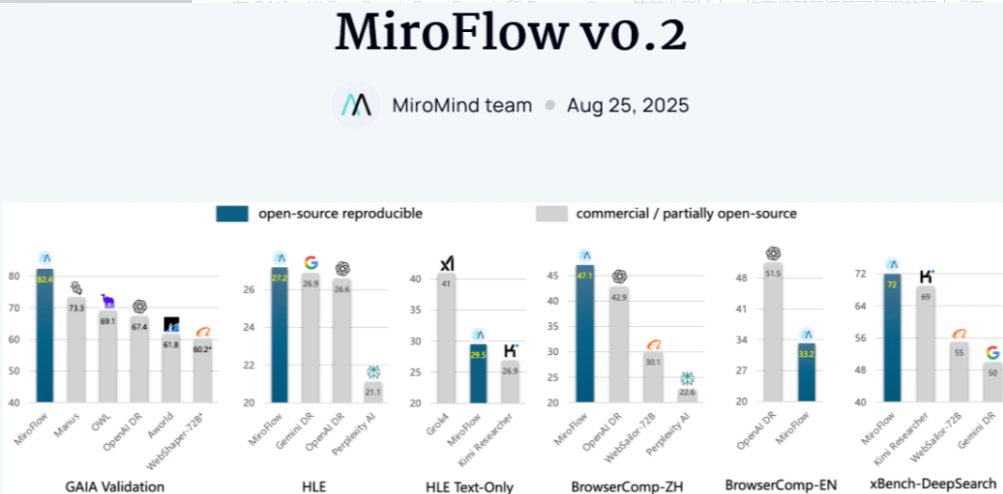
MiroFlow v0.2 – MiroMind开源的研究智能体框架,协调多个工具和子智能体完成任务
MiroFlow v0.2是MiroMind团队开发的开源研究智能体框架,旨在将任意大型语言模型(LLM)的能力提升至媲美OpenAI深度研究级别的水平。其核心设计聚焦于高效、可靠地执行复杂工具调用任...

Qwen3-Max – 阿里通义推出的超大规模模型,支持灵活调用外部工具完成复杂任务
阿里通义旗舰模型Qwen3 - Max重磅登场,性能超过GPT5、Claude Opus4等,位居全球前三,Qwen3-Max 能在几秒内完成成熟程序员大半天才能实现的编程任务,展现出卓越的指令理解和...
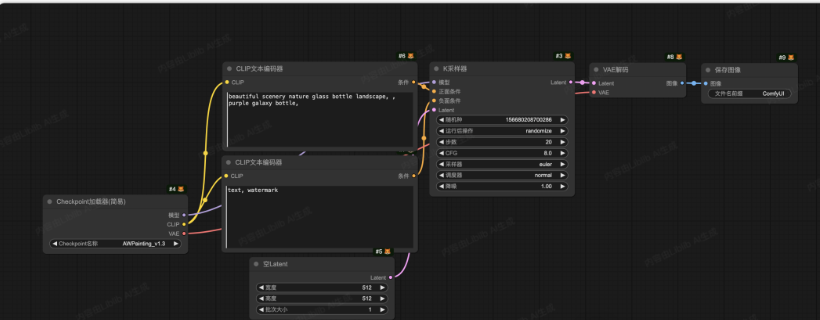
【2025-comfyUI教程】新手必读:ComfyUI 文生图的完整工作原理、节点详解
在 ComfyUI 中,一幅图像的生成其实就是一条“流水线”。它从模型加载开始,到提示词输入,再到采样与解码,最后输出为可见图像。整体逻辑可以概括为以下几个步骤: 1.加载模型(Checkpoint加...

CUDA+cuDNN+pytorch安装,让你的comfyUI起飞!
今天就带大家把CUDA、cuDNN还有pytorch安装一下,让 comfyUI提个速。 在没安装前,我用kontext跑了一张图,时间达到了285秒。 一、安装CUDA 1、在安装前要先确定你的电脑...

如何自定义节点!AI绘画,ComfyUI教程,安装自定义节点
你在网上看到一个非常厉害的 ComfyUI 工作流,下载后却发现不能使用,就像下面这样。 先是一个巨大的提示框,告诉你节点缺失。 叉掉这个提示框后,是一大堆红色的框框,整个工作流根本无法使用。 这是什...