
MemMachine – 开源AI记忆系统,实现高效记忆管理
MemMachine是解决AI Agent长期记忆问题的开源项目,通过双层记忆系统实现真正的记忆功能,而非简单的RAG检索。MemMachine通过情景记忆、语义记忆和用户画像记忆,帮助AI应用学习...

Mistral 3 – Mistral AI推出的最新多模态大模型系列,同时处理文本和图像输入
Mistral 3 是由 mistral ai 正式发布的全新一代开源人工智能模型系列,支持256k超长上下文窗口,可轻松处理百万字长文档、模型支持多模态(文本和图像)与多语言功能。Mistral 3...

twitch官网入口,twitc登录教程
twitch是一款全球超火的游戏直播、教学、玩法攻略流媒体平台,它是美国最大的一家游戏视频直播网站,内容几乎涵盖了市面上所有游戏种类。对跨境电商卖家而言,Twitch是很好的营销引流平台。无论是游戏还...
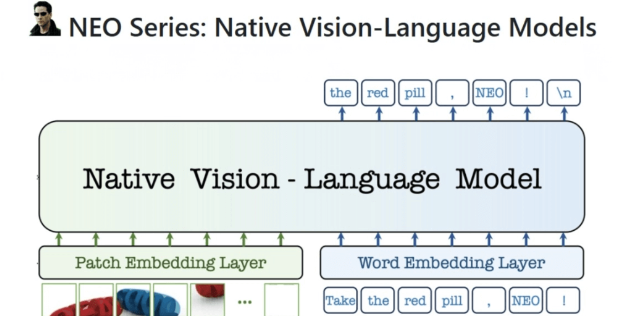
NEO – 商汤联合南洋理工开源的全新多模态模型架构,训练仅需1/10数据量,达到顶尖的视觉感知能力
商汤科技联合南洋理工大学S-Lab发布并开源全新多模态模型架构NEO。该架构号称是行业首个实现深层次融合的原生视觉语言模型,通过原生图块嵌入、三维旋转位置编码和多头注意力机制创新,实现视觉与语言在底层...

Alpamayo-R1 – 英伟达发布首款推理版视觉-语言-动作模型
随着芯片成为AI发展的核心,英伟达发布了新的开源软件Alpamayo-R1,旨在利用人工智能(AI)中的一些最新“推理”技术加快自动驾驶汽车的开发。模型的核心创新包括:构建因果链(CoC)数据集,通过...

PixVerse V5.5 – 爱诗科技推出的视频生成大模型,支持音频和视频同步生成
PixVerse V5.5是爱诗科技推出的最新一代AI视频生成大模型,模型基于自研的多模态视觉语言(MVL)架构,采用Diffusion与Transformer混合设计,支持音画同步生成,简化从构思到...

可灵O1 – 可灵AI推出全球首个统一多模态视频生成模型,轻松生成和编辑视频内容。
全球首个大一统的多模态视频、图片创作工具“可灵O1”正式上线。模型通过创新的多模态视觉语言(MVL)架构,实现视频生成、编辑与理解的无缝融合。可灵O1基于全新的视频和图像模型,以自然语言作为语义骨架...

Vidi2 – 字节跳动推出的多模态视频理解与生成模型,自动剪辑、智能分镜、智能字幕等多种功能
字节跳动推出的视频理解模型Vidi2,通过精准捕捉与识别,在基准测试中取得了显著领先成绩,尤其适用于长视频处理。Vidi2引入了新的基准测试VUE-STG和VUE-TR-V2,以更好地评估STG能力...

Talo – AI实时语音翻译工具,打破语言障碍,增强沟通效果
Talo是一款专为视频通话设计的实时AI翻译工具,旨在打破语言障碍,让全球范围内的无障碍沟通。它利用先进的AI技术,提供即时、准确的语音翻译,用户只需将会议链接粘贴到Talo界面并选择所需语言,即可开...
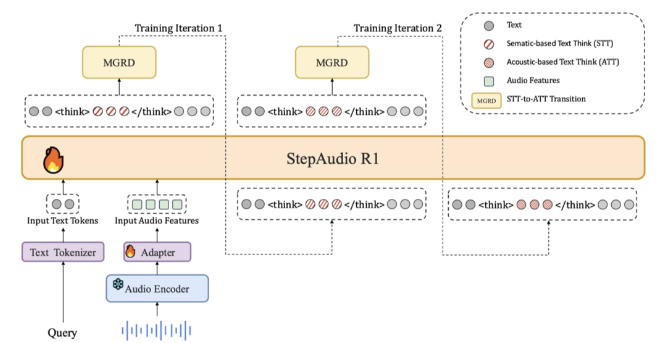
StepAudio R1 – 阶跃星辰推出的全球首个开源原生音频推理模型,真正实现深度推理。
StepAudio R1 是阶跃星辰团队推出的全球首个开源原生音频推理模型。模型通过创新的模态锚定推理蒸馏(MGRD)框架,解决了传统音频模型在复杂推理中性能下降的问题,真正实现基于声学特征的深度推理...