GigaBrain-0 – 最新开源VLA具身模型,打造了全球首个最全具身智能数据体系最新推出的GigaBrain-0是一款基于世界模型(World Model)的视觉-语言-动作(VLA)基础模型,专为机器人复杂操作任务设计。GigaBrain-0通过加入深度信息的输入,提升了物体3...发现资讯4个月前04890
FIBO – 开源的图像生成模型,支持快速迭代和精准控制,提升创意效率。FIBO是一个开源的文本生成图像模型,专为长结构化描述训练而成,能够根据用户输入的文本描述快速生成高质量的图像。支持将简短的文本提示扩展为详细的结构化JSON描述,能将简短的文本提示自动扩展为长达千字...发现资讯4个月前05410
Grokipedia – xAI公司推出的AI 版维基百科,支持多语言无缝切换埃隆·马斯克推出了AI驱动的在线百科全书Grokipedia,这是一个完全由Grok聊天机器人驱动和维护的在线百科全书。该平台目前收录超过88.5万篇文章,所有内容均由AI自主生成和维护。基于xAI的...发现资讯4个月前06450
火山引擎推出的AI视频生成模型– 1.0 pro fast ,速度提升约3倍,成本降低72%火山引擎正式上线豆包视频生成模型 1.0profast。该模型在继承 Seedance1.0pro 模型核心优势的基础上,实现了显著的效率突破:生成速度最高提升约 3 倍,价格直降 72%。pro f...发现资讯4个月前05870
清华联合巨人网络开源的多方言语音合成大模型框架DiaMoE-TTS巨人网络AI Lab与清华大学电子工程系SAT Lab的研究团队联合首创多方言语音合成大模型框架DiaMoE-TTS,并宣布将数据、代码、方法全方位开源,旨在推动方言语音合成的公平与普惠。该框架基于国...发现资讯4个月前05340
UniPixel – 香港理工联合腾讯推出的像素级多模态大模型,实现语言与视觉的深度融合香港理工大学和腾讯ARC Lab的研究团队推出了首个统一的像素级多模态大模型——UniPixel。一个能够无缝集成像素级感知与通用视觉推理能力的大型多模态模型。该模型首次实现了视频理解与精确物体标注的...发现资讯4个月前05850
RTFM – 李飞飞团队推出的实时生成式世界模型,仅需单块H100 GPU可实现交互式体验RTFM是一款基于大规模视频数据进行端到端训练、效率极高的自回归扩散Transformer模型。仅需一块H100 GPU,RTFM模型就能实时渲染出持久且3D一致的场景,无论是真实空间还是虚拟想象场景...发现资讯4个月前06980
Manus 1.5 – Manus最新AI Agent版本,速度提升近四倍,支持Web全栈开发Manus 今日宣布推出全新的 Manus 1.5,这是该公司迄今功能最强的 AI 智能体,在任务执行速度、可靠性与输出质量方面均实现显著提升。Manus 1.5 建立在重新架构的引擎之上,使一切变得...发现资讯4个月前07130
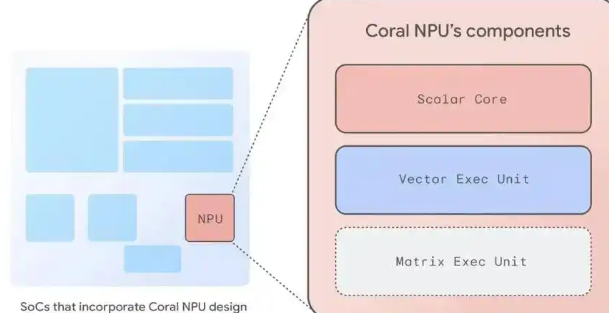
Coral NPU – 谷歌推出的全栈开源AI平台,高效执行机器学习(ML)模型的推理任务谷歌正式推出 Coral NPU,一个面向边缘人工智能(Edge AI)的开源全栈平台。旨在解决性能、碎片化和隐私这三大核心挑战,而这些挑战限制了功能强大、始终在线的 AI 技术在低功耗边缘设备和可穿...发现资讯4个月前05930
DeepSeek-OCR – DeepSeek团队开源的视觉语言模型,实现7-20倍的压缩比。DeepSeek 开源了新模型 OCR 。支持对任意图像进行自由式文字识别,能够快速提取图片中的全部文本信息,不依赖版面结构。能够自动识别并重建文档中的排版结构,包括段落、标题、页眉页脚等,实现“结构...发现资讯4个月前07590