DeepSeek-OCR – DeepSeek团队开源的视觉语言模型,实现7-20倍的压缩比。DeepSeek 开源了新模型 OCR 。支持对任意图像进行自由式文字识别,能够快速提取图片中的全部文本信息,不依赖版面结构。能够自动识别并重建文档中的排版结构,包括段落、标题、页眉页脚等,实现“结构...发现资讯4个月前07590
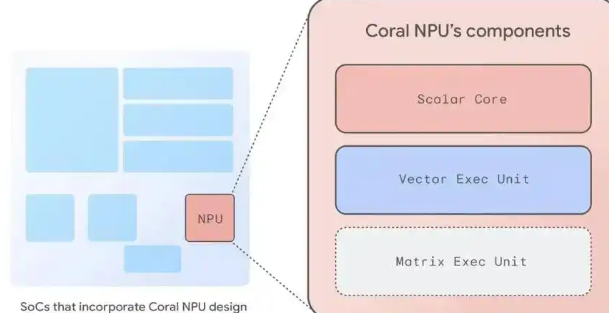
Coral NPU – 谷歌推出的全栈开源AI平台,高效执行机器学习(ML)模型的推理任务谷歌正式推出 Coral NPU,一个面向边缘人工智能(Edge AI)的开源全栈平台。旨在解决性能、碎片化和隐私这三大核心挑战,而这些挑战限制了功能强大、始终在线的 AI 技术在低功耗边缘设备和可穿...发现资讯4个月前05930
Manus 1.5 – Manus最新AI Agent版本,速度提升近四倍,支持Web全栈开发Manus 今日宣布推出全新的 Manus 1.5,这是该公司迄今功能最强的 AI 智能体,在任务执行速度、可靠性与输出质量方面均实现显著提升。Manus 1.5 建立在重新架构的引擎之上,使一切变得...发现资讯4个月前07130
RTFM – 李飞飞团队推出的实时生成式世界模型,仅需单块H100 GPU可实现交互式体验RTFM是一款基于大规模视频数据进行端到端训练、效率极高的自回归扩散Transformer模型。仅需一块H100 GPU,RTFM模型就能实时渲染出持久且3D一致的场景,无论是真实空间还是虚拟想象场景...发现资讯4个月前07080
UniPixel – 香港理工联合腾讯推出的像素级多模态大模型,实现语言与视觉的深度融合香港理工大学和腾讯ARC Lab的研究团队推出了首个统一的像素级多模态大模型——UniPixel。一个能够无缝集成像素级感知与通用视觉推理能力的大型多模态模型。该模型首次实现了视频理解与精确物体标注的...发现资讯4个月前05850
八爪鱼RPA是一款基于机器人流程自动化平台八爪鱼RPA是一款基于机器人流程自动化(Robotic Process Automation, RPA)技术的办公流程自动化工具,旨在通过模拟人类操作,如鼠标点击、键盘输入、数据读取等,实现自动化任务...发现资讯4个月前06750
清华联合巨人网络开源的多方言语音合成大模型框架DiaMoE-TTS巨人网络AI Lab与清华大学电子工程系SAT Lab的研究团队联合首创多方言语音合成大模型框架DiaMoE-TTS,并宣布将数据、代码、方法全方位开源,旨在推动方言语音合成的公平与普惠。该框架基于国...发现资讯4个月前05340
Veo 3.1 – 谷歌推出的AI视频生成模型,能快速生成高质量的视频谷歌正式发布最新一代AI视频生成模型 Veo 3.1,该模型支持生成4秒、6秒或8秒的720P或1080P视频片段并自带音轨,可通过文本提示、图像或视频片段输入生成内容,提供首尾帧插值、场景延展及多图...发现资讯4个月前05650
Local-NotebookLM – 开源PDF转播客AI工具,支持多种音频输出格式Local-NotebookLM是一款开源的AI工具,能够将PDF文档转换为多种风格和格式的音频内容,如播客、访谈、辩论等。它支持自定义音频长度和风格,具备智能PDF解析、多语言支持、灵活模型选择和逼...发现资讯4个月前06540
ZenMux – 全球首个企业级 AI 模型聚合平台最近发现超实用的AI平台——ZenMux,全球首个企业级 AI 模型聚合平台。集成GPT-5、Claude、Gemini、Kimi、DeepSeek、Qwen等全球顶级大模型,为开发者提供统一的 AP...发现资讯4个月前01.4K0