SAIL-VL2 – 字节抖音联合国立大学开源的视觉语言模型,突破传统密集型模型的限制抖音SAIL团队与LV-NUS Lab联合推出的多模态大模型SAIL-VL2。它能高效地将视觉输入对齐到语言模型的表示空间。整个系统由三个核心部分组成:视觉编码器SAIL-ViT、视觉-语言适配器和大...发现资讯5个月前06850
混元图像2.1 – 腾讯开源的文生图模型,支持2K分辨率的图像生成腾讯Hunyuan团队正式开源HunyuanImage2.1,该模型支持原生2048x2048分辨率输出,并显著提升文本生成能力,尤其在双语(中英)支持和复杂语义理解上表现出色。该模型增强了语义一致性...发现资讯6个月前06830
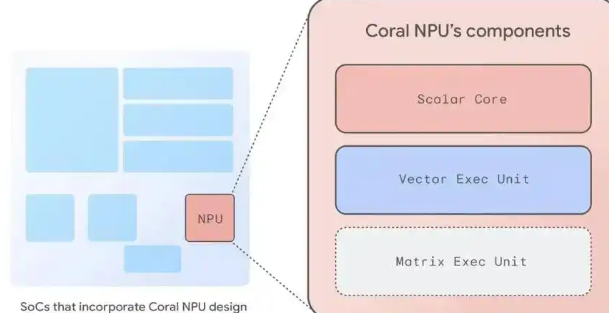
Coral NPU – 谷歌推出的全栈开源AI平台,高效执行机器学习(ML)模型的推理任务谷歌正式推出 Coral NPU,一个面向边缘人工智能(Edge AI)的开源全栈平台。旨在解决性能、碎片化和隐私这三大核心挑战,而这些挑战限制了功能强大、始终在线的 AI 技术在低功耗边缘设备和可穿...发现资讯5个月前06760
WebWeaver – 阿里通义开源的双Agent框架,提高研究效率和质量WebWalker是阿里巴巴通义实验室提出的一个用于提升大型语言模型(LLM)网页信息检索能力的框架,它是一个基于阿里通义大模型(通义千问)的开源框架,旨在通过对话式AI助手(Agent)来提升用户与...发现资讯6个月前06760
Androidify – 谷歌开源的如何构建AI Android应用项目,创建个性化安卓机器人Androidify是谷歌推出的一项开源计划,旨在帮助开发者深入了解如何在 android 平台上打造由人工智能驱动的应用程序。用户可以通过上传个人照片或输入文字描述,生成专属的安卓机器人形象,并自由...发现资讯5个月前06750
Mixboard – 谷歌推出的AI画板工具,快速将想法可视化谷歌推出实验性 AI 工具 Mixboard,该工具由Banana提供支持,号称能把任何想法都即时可视化。主打“开放画布”与生成式 AI 创意,可从文本提示或预制板开始,生成包括家居装饰、产品设计等多...发现资讯6个月前06750
xLLM – 京东开源的智能推理框架,实现5倍效率提升和90%成本优化京东正式开源其自研大模型推理引擎xLLM。据悉,该引擎基于国产芯片深度优化,是一款专注于大模型高效推理的基础软件。xLLM在内部多场景应用中实现的5倍效率提升和90%成本优化,已经强有力地证明了其技术...发现资讯5个月前06730
可灵2.5 Turbo – 可灵推出的最新AI视频生成模型,适合多种风格的视频创作。可灵AI推出视频生成可灵2.5 Turbo模型,同步更新文生视频、图生视频两大功能。可灵 2.5 Turbo 最核心的突破在于文本理解能力的代际升级。与仅能处理简单指令的 2.1 版本不同,新模型可深...发现资讯6个月前06730
360集团推出的L4级智能体系统升级为–-多智能体蜂群360集团正式宣布纳米AI升级为“多智能体蜂群”。这标志着纳米AI成为全球首个真正迈入L4级别的智能体系统,颠覆了以往智能体的工作范式——它实现了智能体从“单兵作战”到“群体协同”的物种级进化,像蜂群...发现资讯8个月前06720
T5Gemma 2 – 谷歌开源的长上下文编码器-解码器模型,支持超过 140 种语言谷歌推出的T5Gemma 2模型坚持使用编码器-解码器架构,该模型能够处理长达128K的上下文信息,显著提升了长文本处理的准确性。参数规模有 270M – 270M、1B – 1B 和 4B – 4B...发现资讯3个月前06680