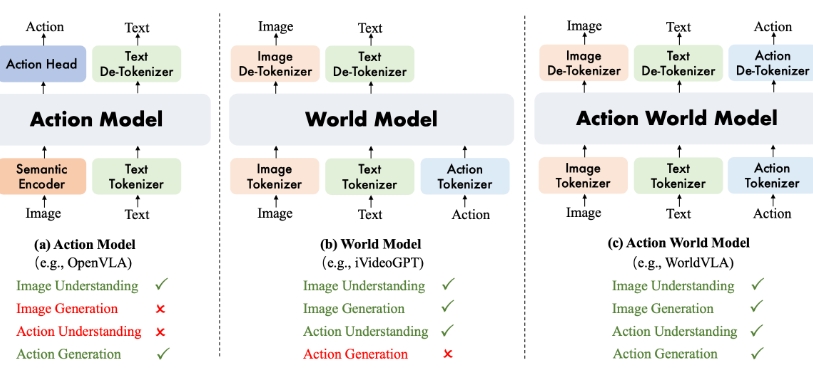

阿里巴巴达摩院提出了 WorldVLA, 首次将世界模型 (World Model) 和动作模型 (Action Model/VLA Model) 融合到了一个模型中。WorldVLA 是一个统一了文本、图片、动作理解和生成的全自回归模型。WorldVLA的技术架构就像一座精心设计的信息处理工厂,其中最核心的是三个专门的编码器,分别负责处理图像、文本和动作信息。模型将视觉-语言-动作(VLA)模型与世界模型整合到一个单一框架中。
模型基于动作和图像理解预测未来的图像,目的是学习环境的基本物理规律以改进动作生成。动作模型根据图像观察生成后续的动作,辅助视觉理解,并反过来帮助世界模型的视觉生成。WorldVLA在性能上优于独立的动作模型和世界模型,突显世界模型与动作模型之间的相互增强作用。为解决自回归方式生成一系列动作时性能下降的问题,提出一种注意力掩码策略,在生成当前动作时选择性地屏蔽先前的动作,在动作块生成任务中显著提高性能。
WorldVLA的主要功能
动作生成:根据图像和语言指令生成后续动作,支持连续动作规划。
图像预测:基于当前图像和动作预测未来图像状态,提升视觉预测精度。
环境理解:学习环境物理规律,增强视觉和动作理解能力。
双向增强:动作模型与世界模型相互促进,提升整体性能。
WorldVLA的技术原理
统一框架:WorldVLA将视觉-语言-动作(VLA)模型和世界模型整合到一个单一的框架中。用三个独立的编码器(图像编码器、文本编码器和动作编码器)将不同模态的数据编码为统一的词汇表中的标记,实现跨模态的理解和生成。
自回归生成:模型用自回归的方式进行动作和图像的生成。动作模型根据历史图像和语言指令生成动作,世界模型根据历史图像和动作预测未来的图像状态。
注意力掩码策略:为解决自回归模型在生成一系列动作时可能出现的性能下降问题,WorldVLA提出一种注意力掩码策略。在生成当前动作时选择性地屏蔽先前的动作,减少错误的传播,提高动作块生成的性能。
双向增强:WorldVLA基于世界模型和动作模型的相互作用实现双向增强。世界模型基于预测未来状态帮助动作模型更好地理解环境的物理规律,动作模型基于生成动作帮助世界模型更准确地预测未来的图像状态。
训练策略:WorldVLA在训练时混合使用动作模型数据和世界模型数据,确保模型能够同时学习到动作生成和图像预测的能力。混合训练策略让模型能在单一架构中实现多种功能。
WorldVLA的应用场景
机器人目标导向任务:帮助机器人根据视觉和语言指令完成目标导向的任务,如将物体从一个位置移动到另一个位置。
复杂环境中的精细操作:在复杂环境中,如杂乱桌面或狭窄空间,生成适应性强的动作,完成精细操作。
人机协作任务:在人机协作场景中,理解人类的动作和意图,生成相应的协作动作,提高协作效率。
未来场景模拟与预测:预测未来的图像状态,帮助机器人提前规划和评估动作后果,如自动驾驶中的道路场景预测。
教育与研究平台:作为教学工具和研究平台,帮助学生和研究人员理解和实践机器人控制和视觉预测的原理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...