近日,上海交通大学人工智能学院Agents团队开发的AI专家智能体「ML-Master」在OpenAI发布的权威基准测试MLE-bench中取得了较好成绩,平均奖牌率为29.3%。微软的RD-Agent平均奖牌率为22.4%,OpenAI的AIDE平均奖牌率为16.9%。
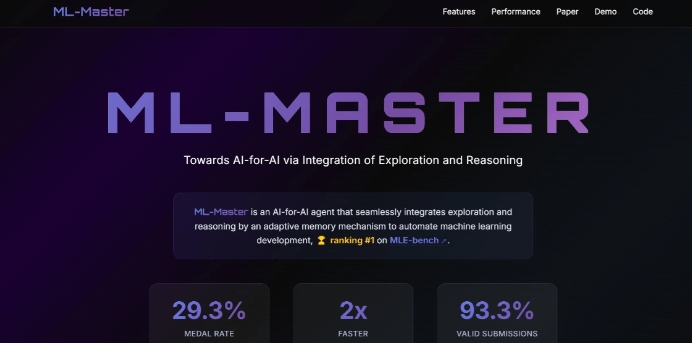
ML-Master通过创新的探索-推理深度融合范式,模拟人类专家的认知策略,整合广泛探索与深度推理,在测试中展现出一定性能。该智能体在75个Kaggle竞赛任务中,93.3%的任务提交有效解,44.9%的任务超越半数人类参赛者。
ML-Master是什么
ML-Master是上海交通大学人工智能学院Agents团队推出AI专家智能体。在OpenAI的权威基准测试MLE-bench中表现出色,以29.3%的平均奖牌率位居榜首,超越了微软的RD-Agent和OpenAI的AIDE等竞争对手。ML-Master通过“探索-推理深度融合”的创新范式,模拟人类专家的认知策略,整合广泛探索与深度推理,显著提升了AI在机器学习工程中的表现。采用平衡多轨迹探索和可控推理两大模块,通过自适应记忆机制实现两者的高效协同。
ML-Master的主要功能
探索与推理深度融合:ML-Master通过创新的“探索-推理深度融合”范式,模拟人类专家的认知策略,整合广泛探索与深度推理,显著提升AI性能。
卓越的性能表现:
在OpenAI的MLE-bench基准测试中,ML-Master以29.3%的平均奖牌率位居榜首,大幅领先微软的RD-.(22.4%)和OpenAI的AIDE(16.9%)。
93.3%的任务提交有效解,44.9%的任务超越半数人类参赛者,展现出强大的泛化能力和稳定性。
计算效率极高,仅用12小时完成测试,计算成本仅为基线方法的一半。
强大的自我演进能力:ML-Master在多轮任务执行过程中持续提升解决方案质量,最终性能相比初始版本提升超过120%。
ML-Master的技术原理
平衡多轨迹探索(Balanced Multi-trajectory Exploration)
MCTS启发的树搜索:将AI研发过程建模为决策树,每个节点代表一个AI方案的状态。
并行探索策略:同时探索多个解决方案分支,突破传统串行探索的限制,大幅提升探索效率。
动态优先级调整:根据每个分支的潜在价值动态分配计算资源,避免无效探索。
可控推理(Steerable Reasoning)
自适应记忆机制:精准提取关键信息,避免信息过载,智能筛选历史探索中的有效信息,确保推理过程基于更相关的知识。
情境化决策:结合具体执行反馈和成功案例进行有根据的分析,避免“拍脑袋”决策。
闭环学习系统:探索结果实时反哺推理过程,形成“探索→推理→优化→再探索”的良性循环。
自适应记忆机制(Adaptive Memory)
智能记忆构建:探索模块自动收集执行结果、代码片段和性能指标,同时选择性整合来自父节点和并行兄弟节点的关键信息。
嵌入推理决策:记忆信息直接嵌入到推理模型的决策部分,确保每次推理都基于具体的历史执行反馈和多样化探索的经验。
协同进化机制:推理结果指导后续探索方向,探索经验持续丰富推理过程,实现探索与推理的深度融合。
ML-Master的项目地址
项目官网:https://sjtu-sai-agents.github.io/ML-Master/
Github仓库:https://github.com/sjtu-sai-agents/ML-Master
ML-Master的应用场景
机器学习任务自动化:ML-Master通过其“探索-推理深度融合”的技术框架,能自动完成从模型训练、数据准备到实验运行的完整机器学习流程。在OpenAI的MLE-bench基准测试中表现出色,证明在处理复杂机器学习任务中的高效性和准确性。
AI开发效率提升:ML-Master通过平衡多轨迹探索和可控推理模块,显著提升了AI开发的效率。适用于需要快速迭代和优化的AI项目。
AI自我演进与优化:ML-Master具备强大的自我演进能力,能在多轮任务执行中持续提升解决方案质量。适用于需要长期优化和自我改进的AI系统,例如在复杂环境下的自适应学习和优化任务。
多领域任务覆盖:ML-Master可以扩展到其他需要AI自主优化的领域,如材料科学、医疗诊断、金融交易等。例如,技术框架可以用于材料属性预测、新材料发现以及生产过程优化。
情感分析与文本处理:ML-Master的技术原理也可以应用于自然语言处理领域,例如情感分析和观点挖掘。能对文本进行语义表示,基于此进行情感分类和观点抽取,适用于消费决策和舆情分析等场景。
本站信息分享,不代表本站观点和立场,如有侵权请联系作者立删。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...