GLM-OCR – 智谱开源的轻量级多模态OCR模型,仅 0.9B 参数智谱正式发布并开源 GLM-OCR。据介绍,该模型仅 0.9B 参数规模,支持 vLLM、SGLang 和 Ollama 部署,模型基于GLM-V架构,集成自研CogViT视觉编码器与轻量跨模态连接层...发现资讯5天前01160
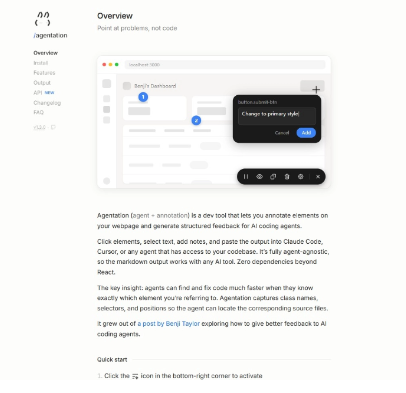
Agentation – AI编程协作工具,支持自动捕获元素,可视化反馈问题转为代码Agentation是一款开源的 ai 编程协同工具,专为提升开发者与 ai 编程助手之间的协作效率而设计,它通过允许用户在网页界面中直接进行可视化标注,将直观的问题反馈自动转化为机器可解析的结构化信...发现资讯5天前02330
Qwen3-TTS – 阿里通义开源的系列语音生成模型,实现精准的语音表达Qwen3-TTS是通义实验室推出的开源语音合成系列模型,集音色复刻、音色定制与精细化语音调控能力于一体,支持客户端实时输入文本并持续接收语音流。模型覆盖10种主流语言(中文、英文、日语、韩语、德语...发现资讯5天前01520
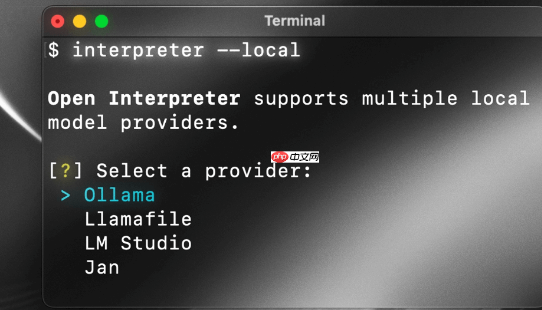
Open Interpreter – 开源AI终端助手,支持在本地环境中运行open interpreter 是一个开源的 ai 终端助手项目,旨在为大型语言模型(llm)赋予本地代码执行能力。通过自然语言交互界面,用户可以通过类似 ChatGPT 的方式在终端中与模型对话...发现资讯5天前02110
n1n – AI大模型API聚合服务平台,全球部署高性能LLM API网关n1n.ai 是一个提供大模型 API 服务的平台,连接全球顶级 AI 模型,具备高可用性、低延迟和多模型支持,提供按需付费模式,价格透明,助力企业和开发者降低成本,快速集成 AI 能力,快速上线 A...发现资讯4周前02570
Voquill – 开源AI语音输入工具,语音输入速度是键盘输入的四倍voquill是一款开源语音输入工具,旨在以语音替代传统键盘输入,可在任何文本框和应用程序中使用,实现系统级的通用兼容性。显著提升写作与信息记录的效率,并利用 AI 自动清理转录内容。定位为一个比打字...发现资讯4周前02020
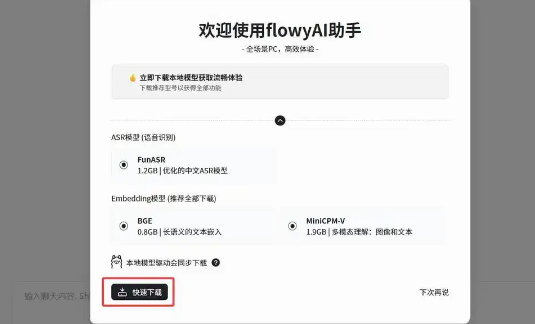
FlowyAIPC – 本地AI办公助手工具,支持多种语言的即时翻译FlowyAIPC 是 Flowy AI 公司推出的面向智能办公领域的 AI 助手产品,这款工具能在完全离线状态下运行,所有数据、聊天记录、知识库内容都保存在本地电脑中,保证了数据的安全性和私密性。它...发现资讯1个月前03060
MovieFlow – AI视频创作平台,自动将文字转化为完整的视频内容MovieFlow AI是一款免费的AI视频生成工具,支持创建最长三分钟的电影级视频,无需预先付费。MovieFlow 内置先进的自然语言处理引擎,用户输入关键词或大致情节后,它能自动生成逻辑清晰、结...发现资讯1个月前03130
MyDetector – AI内容检测平台,对文本进行语法检查和逻辑分析MyDetector 是一款面向学术、媒体、企业与内容创作领域的全能型 AI 内容真实性与质量检测平台,MyDetector 核心功能包括 AI 内容检测、抄袭检查、语法与逻辑分析,以及文本“人类化...发现资讯1个月前02900
T5Gemma 2 – 谷歌开源的长上下文编码器-解码器模型,支持超过 140 种语言谷歌推出的T5Gemma 2模型坚持使用编码器-解码器架构,该模型能够处理长达128K的上下文信息,显著提升了长文本处理的准确性。参数规模有 270M – 270M、1B – 1B 和 4B – 4B...发现资讯1个月前03210